Posts
-
One-line Algorithmic Music in XNA

-
Scrolling Textures with Zoom and Rotation

-
Adding a Skybox to RenderMonkey

-
RenderMonkey Beginner's Tutorial

-
Limiting 2D Camera Movement with Zoom
-
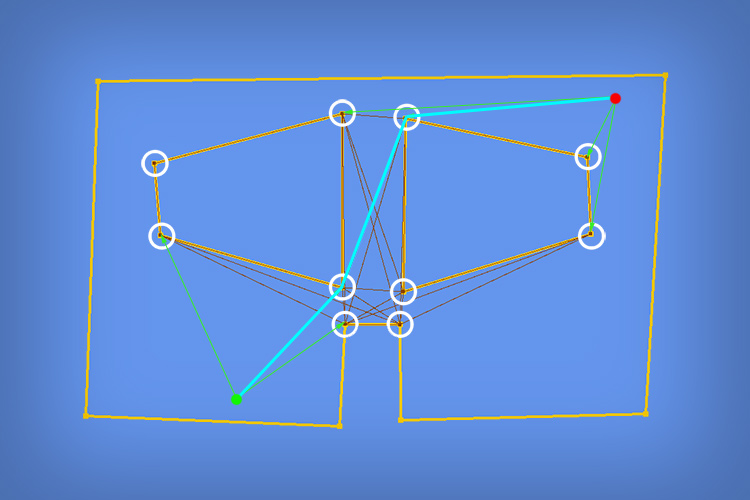
Pathfinding on a 2D Polygonal Map
-
Creating a Basic Synth in XNA 4.0 - Part III

-
2D Camera with Parallax Scrolling in XNA

-
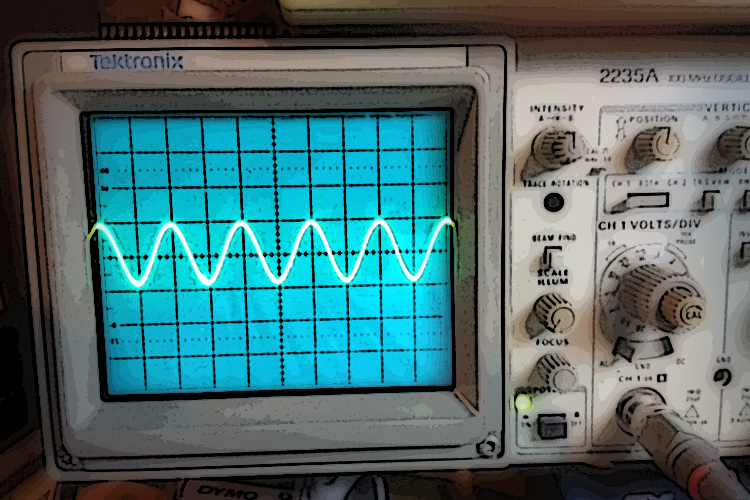
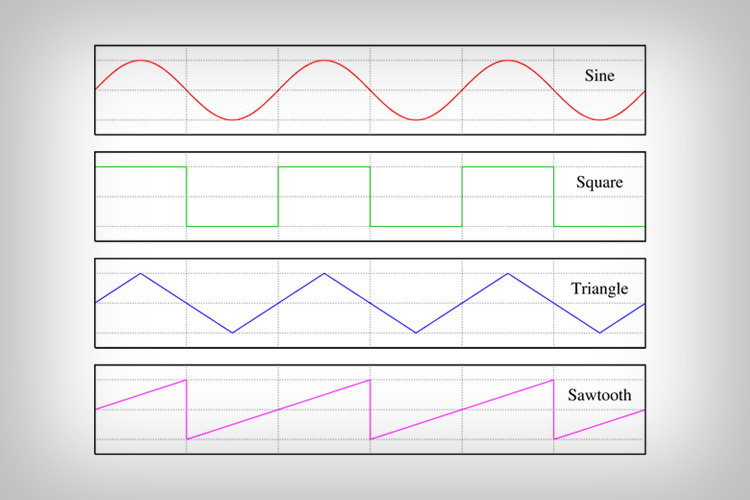
About Oscillators
-
Creating a Basic Synth in XNA 4.0 - Part II

-
Rendering Mathematical Functions in XNA
-
Problems with DesignMode in WinForms

-
Creating a Basic Synth in XNA 4.0 - Part I

-
Circular Increment

-
Scrolling Textures in XNA

subscribe via RSS