Creating a Basic Synth in XNA 4.0 - Part II

Hello folks, and welcome to part II of my Creating a Basic Synth in XNA 4.0 series!
This time I’ll be covering the DynamicSoundEffectInstance class and how to put some of the concepts we discussed earlier into practice. Therefore (if you haven’t done so already) I recommend that you read part I before proceeding. I’d also like to warn you that this article will be quite long. The good news is that this is the hardest part for a beginner to overcome, and future articles on this series will probably be smaller and in general easier to grasp.
By the way, there’s a video sample at the end of the article in case you’d like to see it in action before you start reading!
Summary
I’ll start with a summary of everything that has been discussed already in part I:
- Sound is the way our brain interprets the pressure oscillations that reach our eardrums.
- These pressure oscillations can be mathematically represented as waves.
- The wave’s basic relation to sound is that amplitude equals volume, frequency equals pitch and shape equals tone.
- A wave can be implemented (in code) as any regular function that returns an amplitude given a specific time input (e.g. double wave(double time)).
- Even though a wave is a continuous function you can approximate it by sampling only a “few” points along the way.
Introduction
Using this knowledge to generate our own sounds in XNA 4.0 is possible because of a new class called DynamicSoundEffectInstance which exposes all of the necessary low-level access. In theory, the whole process is pretty straightforward: you create some function that represents the sound wave you’d like to playback, read (or sample) enough values from that function to get a decent representation, and feed all of them to XNA which routes them through the low-level audio engine that takes care of the rest. In practice however, it’s not that easy because of a few important details that you will have to know in order to use the class properly:
- (Configuration) The DynamicSoundEffectInstance class is flexible enough to support different sample rates and multiple channel configurations. You’ll need to understand these concepts and set the parameters accordingly.
- (Format) The DynamicSoundEffectInstance class expects the data you submit to be presented in a very specific way. As we’ll see, this format is not exactly the easiest to work with when doing our wave calculations.
- (Chunks) Even if you have a large amount of sound data, you (most likely) won’t be submitting all of it at once, since that would be slow. Instead, in order to enable real-time behavior you’ll be dividing your data in small chunks and submitting them one at a time.
And I’ll admit that some of these details can be pretty confusing if you’ve never seen anything like this before. It did take me some time before finally getting that “a-ha” moment. Therefore, let’s take it one step at a time. I’ll describe each step you need to implement in order to use the DynamicSoundEffectInstance class, and present my solutions to the problems encountered during the way. Let’s start!
The Steps
In order to create and use the DynamicSoundEffectInstance class, you’ll need to follow these four steps:
- Create and configure a DynamicSoundEffectInstance object.
- Create a buffer to hold your audio samples.
- Fill the buffer with meaningful values.
- Submit the buffer to the DynamicSoundEffectInstance object when needed.
Step 1: Create DynamicSoundEffectInstance
If you’ve used XNA’s SoundEffect API before, then you might already be familiar with the SoundEffect and SoundEffectInstance classes. When using the content pipeline to load sound effects for your game, you receive a SoundEffect object that can be used to playback that sound. You can also use the SoundEffect.CreateInstance() method to create single instances of that SoundEffect for individual control. Either way, when loading a sound resource through the content pipeline, all of its data is automatically copied into the object’s audio buffer, and the sound engine only needs to start playing it when requested.
On the other hand, the DynamicSoundEffectInstance class (which inherits from SoundEffectInstance) is created with an empty audio buffer, and instead allows you to fill it with data. But since you’re the one providing it with all of the data, there are some extra decisions you need to take on how the data should be interpreted. Some of these parameters are already fixed for you by the framework while others are selected when creating the DynamicSoundEffectInstance object. Either way it’s important to know exactly what they mean, so I’ll describe them one by one.
Let’s start by taking a look at DynamicSoundEffectInstance’s constructor:
public DynamicSoundEffectInstance (int sampleRate, AudioChannels channels)
As you can see, there are two parameters that you need to pass to the constructor: the sample rate and the audio channels count.
Sample Rate
As explained in part I of this article, the sample rate describes how many audio samples (remember, a sample is exactly one value taken from our wave function) will be processed every second (for each audio channel). Having a larger sample rate is desirable because it means that you can better represent fast variations in the sound and higher frequencies. The XNA Framework lets you select a sample rate ranging from 8.000 Hz to 48.000 Hz. Audio CD’s use a sample rate of 44.100 Hz so if you’re creating a music application you’ll probably want to use at least that for best results.
Audio Channels Count
You’ve probably heard the words Stereo and Mono before. The main difference between them is that with Mono (1 audio channel), even if you have a pair of speakers, they will both emit the same sound, whereas with Stereo (2 audio channels) you have the freedom to specify different sounds for each speaker (left and right). It’s natural then that with Stereo you’ll need to hold twice the amount of information. The XNA Framework currently supports two possible configurations: AudioChannels.Mono (1 audio channel) and AudioChannels.Stereo (2 audio channels).
Besides these two parameters, there are also a couple things that you do not have control over (because XNA enforces them for you), but should still understand:
Bit Depth
__The bit depth describes how many bits of precision will be used to encode each sample. A larger bit depth implies that you’ll have more precision when dealing with small variations of amplitude in your wave, and get a digital representation that is closer to the original analog wave. When working with waves you’ll normally be generating floating-point samples (usually between -1.0 and 1.0). The problem is that XNA’s audio engine does not work with floating-samples directly. Instead, it works with a fixed bit depth of 16 bits/sample (signed). So basically, you’ll need to convert each of your floating-point samples (in the -1.0 to 1.0 range) to a short (signed 16-bit integer) sample (in the short.MinValue to short.MaxValue) range before feeding them to XNA.
Audio Format
We’ve just seen that XNA forces a signed 16-bit integer bit depth. That’s only one part of the audio format, namely the one which specifies how each audio sample is represented. But we’ve also seen that by choosing a Stereo configuration you can have two audio channels playing simultaneously. The samples for each audio channel will have to be packed into the same buffer, so how are they organized in relation to each other? Well, when you have only one audio channel, each sample is simply stored in the buffer in same the order they appear. But if you have two audio channels, then it’s a different story. Instead, you’ll have to interleave one audio sample from the left channel with one audio sample from the right channel, and repeat until there are no more samples left (i.e. LRLRLRLRLR etc.). Naturally, you’ll also be needing a buffer with twice the size in order to fit all the samples there. I’ll touch this subject again when describing how to create the audio buffers.
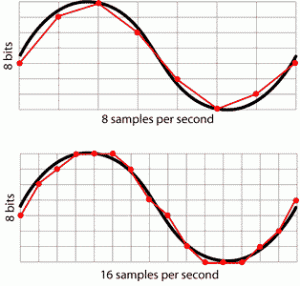 Sample Rate (Horizontal) and Bit Depth (Vertical)
Sample Rate (Horizontal) and Bit Depth (Vertical)
Okay, now that you understand most of the necessary concepts, let’s start putting it to practice and create that DynamicSoundEffectInstance object. I’ll be working with a sample rate of 44.100 Hz and Stereo audio for the rest of this article, since it covers most of the edge cases. Here’s the code for this step:
// On your class
private const int SampleRate = 44100;
private const int ChannelsCount = 2;
private DynamicSoundEffectInstance _instance;
// On LoadContent
_instance = new DynamicSoundEffectInstance(SampleRate, (ChannelsCount == 2) ? AudioChannels.Stereo : AudioChannels.Mono);
Step 2: Create Audio Buffers
This is possibly the hardest step to understand in the whole process, because it depends on most of the concepts we’ve just seen. Let’s start from the beginning. A buffer is simply an array of values, and you’ll need to create one big enough to hold the audio data that will be passed to audio engine. But how big should it be, and in what format should it be created?
Size
The first step is to decide how many audio samples (per channel) do you want to submit to XNA at a time (i.e. on each submit operation). To avoid confusion with the physical size of the buffers we’ll be creating, I’ll call this amount “SamplesPerBuffer” from now on. This is an arbitrary value, so you can choose whatever you like, but depending on your choice, there are a few implications. Depending on the size you choose, the audio engine could become unstable, and you’ll have drops in the audio signal and glitches. Also depending on the size you choose, the latency of your signal will change, which in pratical terms determines how fast your application will be able to react to user input. The rules of thumb are:
Big Buffer = More Stable (Good), More Latency (Bad)
Small Buffer = Less Stable (Bad), Less Latency (Good)
Ideally you’ll want to choose a value that is small enough for latency to be near real-time, but large enough not to hear any sound glitches. I usually start around 3000 and then tweak it to my needs. On my Windows machine I can get it down to about 1000 or less and it still works perfectly.
Format
So, we’ve decided that each buffer should hold, for instance, 3000 audio samples (as I said, experiment with this value). Now what format should our buffer have? That’s where it gets tricky. The thing is, the format that is more convenient for doing wave calculations is not the same that XNA expects to receive.
In order to ease this step, I like to create two different buffers: one to do all of our wave math calculations (which I’ll call that the “Working Buffer”), and a different one to actually comunicate with XNA (which I’ll call the “XNA Buffer”). I’ll provide a method that will convert samples from one format to the other so you won’t have to worry about XNA’s internal format at all. Now on to our buffer formats:
Working Buffer Format
- Our wave function outputs floating-point samples.
- Each audio channel will be generated and stored separatedly.
So we’ll create a bi-dimensional floating-point array depending on the number of channels, like so:
Working Buffer = float[ChannelsCount, SamplesPerBuffer]
XNA Buffer Format
- XNA expects each sample to be a signed 16-bit integer (or short).
- XNA expects both audio channels to be passed together, in an interleaved fashion (LRLRLRLRLR).
- Important: Even though samples are expected to be 16-bit (short), for compatibility reasons XNA accepts its buffer as an array of bytes (8-bit)! This means that you’ll have to encode each of your 16-bit (short) samples as two consecutive 8-bit (byte) samples instead.
Point 3 is very important because it means that you’ll have to multiply the whole size of your buffer by 2 in order to hold all the necessary bytes (which will be 2 bytes for each sample). Since everything will be stored in a row, we use a uni-dimensional array, like so:
XNA Buffer = byte[ChannelsCount * SamplesPerBuffer * 2]
(where 2 is the number of bytes per sample)
I created this image that should help you visualize better how the two buffers are related. The buffer in the middle is never really created, but serves to illustrate how we need to convert our samples from floats/doubles to shorts, before splitting them up into bytes (click to see in full size).
 Audio Buffers
Audio Buffers
That’s all there is to it. As long as you create these arrays with the right size and format, you should be okay. Here’s the code:
// On your class
public const int SamplesPerBuffer = 3000;
private float[,] _workingBuffer;
private byte[] _xnaBuffer;
// On LoadContent, after creating the DynamicSoundEffectInstance object
_workingBuffer = new float[ChannelsCount, SamplesPerBuffer];
const int bytesPerSample = 2;
_xnaBuffer = new byte[ChannelsCount * SamplesPerBuffer * bytesPerSample];
And the method I mentioned before that converts the contents of the working buffer into the xna buffer is (just add it to your class, it’s an utility method):
private static void ConvertBuffer(float[,] from, byte[] to)
{
const int bytesPerSample = 2;
int channels = from.GetLength(0);
int samplesPerBuffer = from.GetLength(1);
// Make sure the buffer sizes are correct
System.Diagnostics.Debug.Assert(to.Length == samplesPerBuffer * channels * bytesPerSample, "Buffer sizes are mismatched.");
for (int i = 0; i < samplesPerBuffer; i++)
{
for (int c = 0; c < channels; c++)
{
// First clamp the value to the [-1.0..1.0] range
float floatSample = MathHelper.Clamp(from1, -1.0f, 1.0f);
// Convert it to the 16 bit [short.MinValue..short.MaxValue] range
short shortSample = (short) (floatSample >= 0.0f ? floatSample * short.MaxValue : floatSample * short.MinValue * -1);
// Calculate the right index based on the PCM format of interleaved samples per channel [L-R-L-R]
int index = i * channels * bytesPerSample + c * bytesPerSample;
// Store the 16 bit sample as two consecutive 8 bit values in the buffer with regard to endian-ness
if (!BitConverter.IsLittleEndian)
{
to[index] = (byte)(shortSample >> 8);
to[index + 1] = (byte)shortSample;
}
else
{
to[index] = (byte)shortSample;
to[index + 1] = (byte)(shortSample >> 8);
}
}
}
}
The method is heavily commented in order to explain what’s going on, but if you have any question about it, feel free to leave it in the comment section below.
Step 3: Fill Buffers
Now that you’ve gotten here, the rest is actually quite easy! Remember that any calculations you do will be stored in the Working Buffer. Then at the end, you simply use the ConvertBuffer method above to copy it to the XNA buffer in the right format. For the sake of keeping it easy, we’ll be using a simple sine wave function that is described like this:
double SineWave(double time, double frequency)
{
return Math.Sin(time * 2 * Math.PI * frequency);
}
Then we’ll be filling our working buffer, such that the left and right audio channels are playing sine waves of different frequencies (in order to clearly demonstrate the effects of stereo audio). Generating waves of different frequencies is pretty straightforward, since you just need to pass a different “frequency” parameter to the function. But what value do we pass to the “time” parameter? We need a way to know, for each individual sample we’re generating, at what time that sample corresponds to. For that we need to create some sort of timer.
First, create a variable to count how much time has passed so far:
// On your class
private double _time = 0.0;
But instead of incrementing it in our Update method as you’re probably used to, we should increment it whenever we advance to the next sample during generation. Calculating how much we should advance our time variable is also easy. We know, for instance, that if we have a SampleRate of 44100 Hz, this means that there will be 44100 samples in a second. Therefore, we can also deduce that each sample has a duration of 1 / 44100 seconds! So basically all we have to do is advance our time variable in (1 / SampleRate) increments, and our variable will always hold a very accurate representation of time (just check the example code below).
So let’s put this all together and create a FillWorkingBuffer() method that fills our buffer with values from the SineWave function above, while automatically counting the time for us. Note that this function is generating a 440 Hz sine wave for the left channel, and a 220 Hz sine wave for the right channel:
private void FillWorkingBuffer()
{
for (int i = 0; i < SamplesPerBuffer; i++)
{
// Here is where you sample your wave function
_workingBuffer[0, i] = (float) SineWave(_time, 440); // Left Channel
_workingBuffer[1, i] = (float) SineWave(_time, 220); // Right Channel
// Advance time passed since beginning
// Since the amount of samples in a second equals the chosen SampleRate
// Then each sample should advance the time by 1 / SampleRate
_time += 1.0 / SampleRate;
}
}
Also don’t forget to call ConvertBuffer() at the end in order to convert your working buffer into XNA’s format!
Step 4: Submit Buffer
All that’s left is to call Play() on our DynamicSoundEffectInstance object and start submitting buffers to it. Submitting the buffer itself is pretty trivial, all you need to do is call:
DynamicSoundEffectInstance.SubmitBuffer(byte[] buffer)
Since filling, converting and submiting a buffer is usually done in sequence, let’s group all three operations in a function for ease of use:
private void SubmitBuffer()
{
FillWorkingBuffer();
ConvertBuffer(_workingBuffer, _xnaBuffer);
_instance.SubmitBuffer(_xnaBuffer);
}
We’re almost there. There’s only one question remaining! How do I know when it’s time to submit a new buffer? There are two different ways to accomplish this:
- Hook the DynamicSoundEffectInstance.BufferNeeded event and submit it there.
- Poll DynamicSoundEffectInstance.PendingBufferCount in your update loop and decide yourself when to submit.
I prefer way number 2 because it allows me to keep a consistent amount of buffers in reserve, which prevents audio glitches and dropouts. I tried doing that with the BufferNeeded event (method 1), and when monitoring my PendingBufferCount value, it would keep fluctuating around every second, whereas with method 2 it stays stable. Furthermore, it’s really easy! All you need to do is add this to your Update method:
// On Update
while(_instance.PendingBufferCount < 3)
SubmitBuffer();
At last, simply call Play() on your DynamicSoundEffectInstance object after creating the buffers and preparing everything, in order to start playback of your sound!
// At the end of LoadContent
_instance.Play();
Sample
Here’s a sample video and source code showing everything described in this article put into practice. You’ll probably notice that there’s many different types of waves being generated (sine, square, pulse, triangle, sawtooth, noise). Since this article became big enough as it is, I’ll be covering those in a separate article dedicated to describing the Oscillator class I’m using on the sample. An oscillator is basically a device that creates wave signals for you. Don’t worry, it’s not complicated at all compared to what we already did.
Conclusions
That’s it! I know it was long, but by now you hopefully have an annoying buzzing sound playing on your speakers. There’s still many things missing though, most notably:
- You can’t play more than one sound at once (like a piano, i.e. we lack polyphony).
- You can’t control the note’s durations (i.e. when they start and stop, etc)
These are the two questions that I’ll address in part III of the series, which will show you how to create a little playable “piano” with dynamically generated audio. It will also describe how to start shaping all of this code into a framework so that we can have more flexibility to add new sounds, effects and other goodies in the future. Meanwhile, be sure to also check my article about oscillators in sound synthesis. Until then!